
ICYMI: Anthropic and Google both dropped SoTA models within the same week: Claude Opus 4.5 on November 24, and Gemini 3 Pro on November 18. So for a few days, Gemini 3 Pro was regarded as the most impressive model yet, until Opus 4.5 proved even stronger for many tasks (esp. anything programming-related).
We’ve tried both for engineering tasks and the results impressed us.
What this means for engineers using AI agents
Over the past 6 months, Claude’s models have been the industry-standard for dev tasks. The general consensus is that Claude follows directions better than Gemini, but sometimes has lower code quality. Gemini models tend to hallucinate more, but they’re faster and have larger context windows.
Researchers are still trying to find the best way to evaluate LLMs at engineering tasks, but for now, SWE-bench Verified is the leading benchmark. Both models have since been ranked:
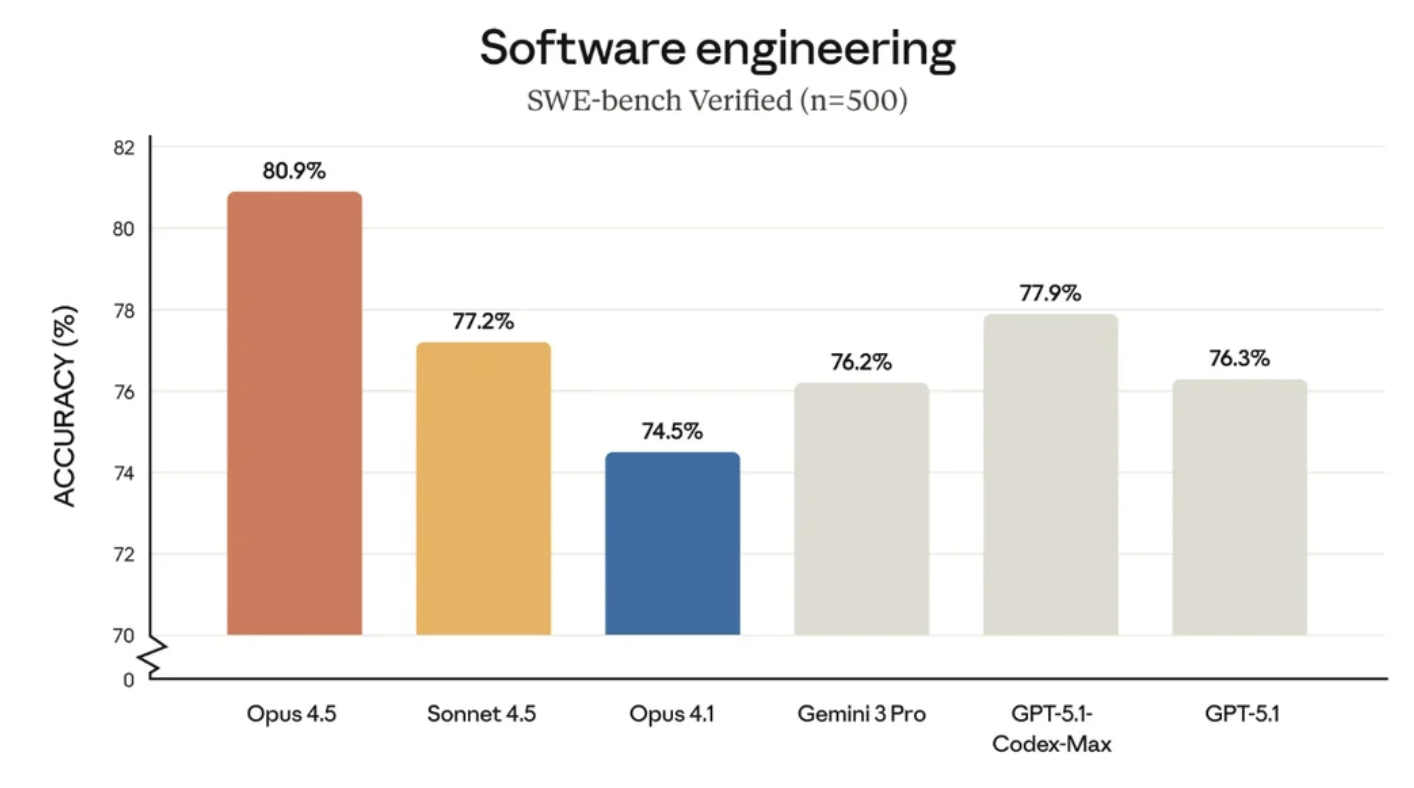
Impressively, Claude Opus 4.5 scored 80.9%. As shown in the diagram, its the first model to break 80%. Gemini 3 Pro is pretty close: it hit 76.2% (but still is weaker than Sonnet 4.5 at 77.2%).
For terminal-based coding agent tasks, Claude is still stronger. On Terminal-bench 2.0 (tool use and computer control), Opus got 62.4% and Gemini’s scored 54.2%.
Gemini is particularly strong at vision tasks: it scored 81% on MMMU-Pro and 87.6% on Video-MMMU. This is obviously less important for engineering tasks, but on occasion you might want to process screenshots, architecture diagrams, or even videos.
Cost to use these models
If you’re using agents everyday to write code, these models end up delivering a pretty good ROI. Both models’ lower tiers cost a fraction (Claude Pro is only $20/mo and includes limited Opus 4.5 usage, and Gemini is free), but the performance/accuracy leap can be well worth it for power users.
We don’t recommend directly buying API tokens if you’re using these for engineering tasks, but that is an option if you want to try each one briefly for ~$5 before committing.
Claude Opus 4.5: You’ll need Claude Pro at $20/month minimum to use Opus 4.5. For $100+ per month, Max gives you priority access and higher usage limits, but you won’t get unlimited Opus 4.5 tokens.
Gemini 3 Pro: For the first three months, you can subscribe to Google AI Ultra at $125/month (increases to $250/mo after). You also get access to Gemini 3 Pro, Deep Think mode, and the Gemini Agent features.
If you’re using the APIs directly: Opus is $5 input/$25 output per million tokens. Gemini is $2/$12 (for the under-200K context window) or $4/$18 (over 200K).
The agent experience
Opus 4.5 works with Claude Code, and has an upgraded Plan Mode. The agent asks for clarification your prompt, and generates a plan.md file that you can edit. Then, CC will start writing code. You can run multiple Claude Code sessions in parallel (one agent debugging, another updating docs, etc).
Opus 4.5 also has three levels of “effort” in beta. This param determines how many tokens Claude will sink into a prompt, and the (likely) resulting code quality.
Gemini 3 Pro ships with Google Antigravity, Google’s new agentic IDE. However, for those who prefer a terminal-based agent, you can also use it with Gemini CLI.
Similar to Claude’s, Gemini 3 Pro has its own “thinking level”, which defaults to “high”.
TLDR: which wins for software engineers?
Both models are obviously highly impressive, but we’ve found that Claude Opus 4.5 is stronger for writing code and using with coding agents. Gemini 3 Pro is better for architecting, coming up with high-level plans, or longer tasks (like refactoring).
If you have the budget, it can be worth subscribing to both and keeping each one siloed.
Environments for your agents
When you’re using agents with Claude or Gemini to ship faster, you’ll need somewhere for your agents to test their code. Shipyard automatically spins up environments for every branch, and agents can grab logs and run tests against these using the Shipyard MCP. Try it free today.


